

|
||||||||||||||||||||||||
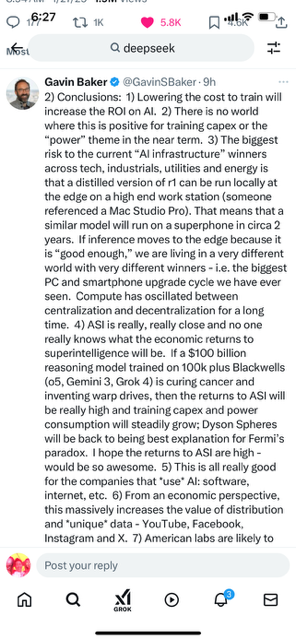
1) DeepSeek r1 is real with important nuances. Most important is the fact that r1 is so much cheaper and more efficient to inference than o1, not from the $6m training figure. r1 costs 93% less to *use* than o1 per each API, can be run locally on a high end work station and does not seem to have hit any rate limits which is wild. Simple math is that every 1b active parameters requires 1 gb of RAM in FP8, so r1 requires 37 gb of RAM. Batching massively lowers costs and more compute increases tokens/second so still advantages to inference in the cloud. Would also note that there are true geopolitical dynamics at play here and I don’t think it is a coincidence that this came out right after “Stargate.” RIP, $500 billion – we hardly even knew you.
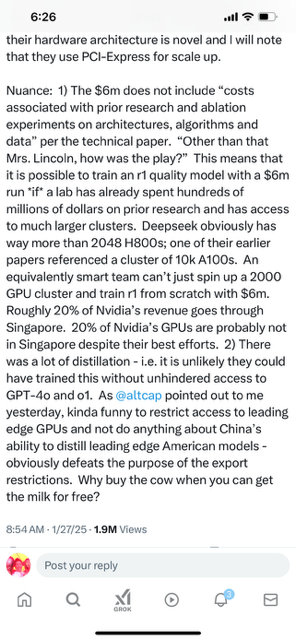
Real: 1) It is/was the #1 download in the relevant App Store category. Obviously ahead of ChatGPT; something neither Gemini nor Claude was able to accomplish. 2) It is comparable to o1 from a quality perspective although lags o3. 3) There were real algorithmic breakthroughs that led to it being dramatically more efficient both to train and inference. Training in FP8, MLA and multi-token prediction are significant. 4) It is easy to verify that the r1 training run only cost $6m. While this is literally true, it is also *deeply* misleading. 5) Even their hardware architecture is novel and I will note that they use PCI-Express for scale up.
Nuance: 1) The $6m does not include “costs associated with prior research and ablation experiments on architectures, algorithms and data” per the technical paper. “Other than that Mrs. Lincoln, how was the play?” This means that it is possible to train an r1 quality model with a $6m run *if* a lab has already spent hundreds of millions of dollars on prior research and has access to much larger clusters. Deepseek obviously has way more than 2048 H800s; one of their earlier papers referenced a cluster of 10k A100s. An equivalently smart team can’t just spin up a 2000 GPU cluster and train r1 from scratch with $6m. Roughly 20% of Nvidia’s revenue goes through Singapore. 20% of Nvidia’s GPUs are probably not in Singapore despite their best efforts. 2) There was a lot of distillation – i.e. it is unlikely they could have trained this without unhindered access to GPT-4o and o1. As @altcap pointed out to me yesterday, kinda funny to restrict access to leading edge GPUs and not do anything about China’s ability to distill leading edge American models – obviously defeats the purpose of the export restrictions. Why buy the cow when you can get the milk for free?

WordPress’d from my personal iPhone, 650-283-8008, number that Steve Jobs texted me on
https://www.YouTube.com/watch?v=ejeIz4EhoJ0

 Duck9 is a credit score prep program that is like a Kaplan or Princeton Review test preparation service. We don't teach beating the SAT, but we do get you to a higher credit FICO score using secret methods that have gotten us on TV, Congress and newspaper articles. Say hi or check out some of our free resources before you pay for a thing. You can also text the CEO:
Duck9 is a credit score prep program that is like a Kaplan or Princeton Review test preparation service. We don't teach beating the SAT, but we do get you to a higher credit FICO score using secret methods that have gotten us on TV, Congress and newspaper articles. Say hi or check out some of our free resources before you pay for a thing. You can also text the CEO:







